Hi there
I’ve been observing a strange behaviour when training my model on renku. After several hours training seems to pause and only continues when I reconnect via VPN and reload my browser. I noticed it by checking how frequently Tensorboard was written; at some point there were no more updates written to it. This happened several times now. Last time I started training on Friday, April 15th around 4pm and it continued until 22:51 the same day. After that it stopped (at epoch 35 out of 500, no early stopping) and I could only get it back to running by connecting to renku again. After that training would automatically resume at epoch 36. But it looks like to me that in between these hours no progress has been made.
See screenshots of Tensorboard below which indicate the timing (epoch 0 to 35), and notice the huge time gap between epoch 35 and 36 on 16.4. at 11:31 (this is right after I reconnected to renku). Also note that I haven’t killed the renku session or turned off my laptop. I know that it went to sleep mode and that my vpn client got disconnected. However, as far as I know this should be the problem as the job has been submitted to the renku machine and I would expect it to just keep running even though there’s no vpn connection established during the whole training time. Also note that I don’t run training in jupyter notebook, I call my python script from the terminal within the visual studio code extension in renku (python src/main.py)
I’d appreciate your support on this as it’s been quite annoying. I am losing valuable training time by having my model just sitting there on idle.


This is on renku limited and a project with 2 GPUs.
Hi can please somebody look into this?
I am losing days of work because the training is not working properly.
Thank you.
@rwagner it could be that the problems you are experiencing are tied to the vscode extension. What happens if you run your model straight from the terminal in jupyterlab? I wonder if the vscode extension goes idle after some time of inactivity or puts things to sleep.
Otherwise, all looks good from my end - I do not see any issues with your session. Also I see that you are starting another session with 2 gpus. This will not work since there are simply not enough GPUs on limited. There are 4-5 in total for the whole cluster. Usually on limited it is hard to get even a session with 1 gpu because all are usually taken.
Another thing that you can check @rwagner is whether the GPUs are utilized (and how much) when you run your models. Right now I do not see any GPU usage on any of your sessions. But it could just be that you are not currently running anything at all and this is expected.
When you start the models you can run nvidia-smi in a terminal to see how much each of your 2 gpus are utilized.
Hi thanks for getting back to me.
Yeah, I know how to monitor GPUs, I usually use the watch command. When I set off training, their usage is between 65% and 99% so I assume this is okay.
However, training doesn’t work either if I spin it off from a juypter notebook (instead of within visual studio code). I am calling my script using the exclamation point/bang (!python src/main.py) to execute the terminal command. Just did so yesterday night (22.4 at 23:36) and when I looked at it again today (23.4. around 12:20) and reconnected my VPN I got a 503 server error (see screenshot below).
The whole session seems to have stopped somehow (see screenshot below).
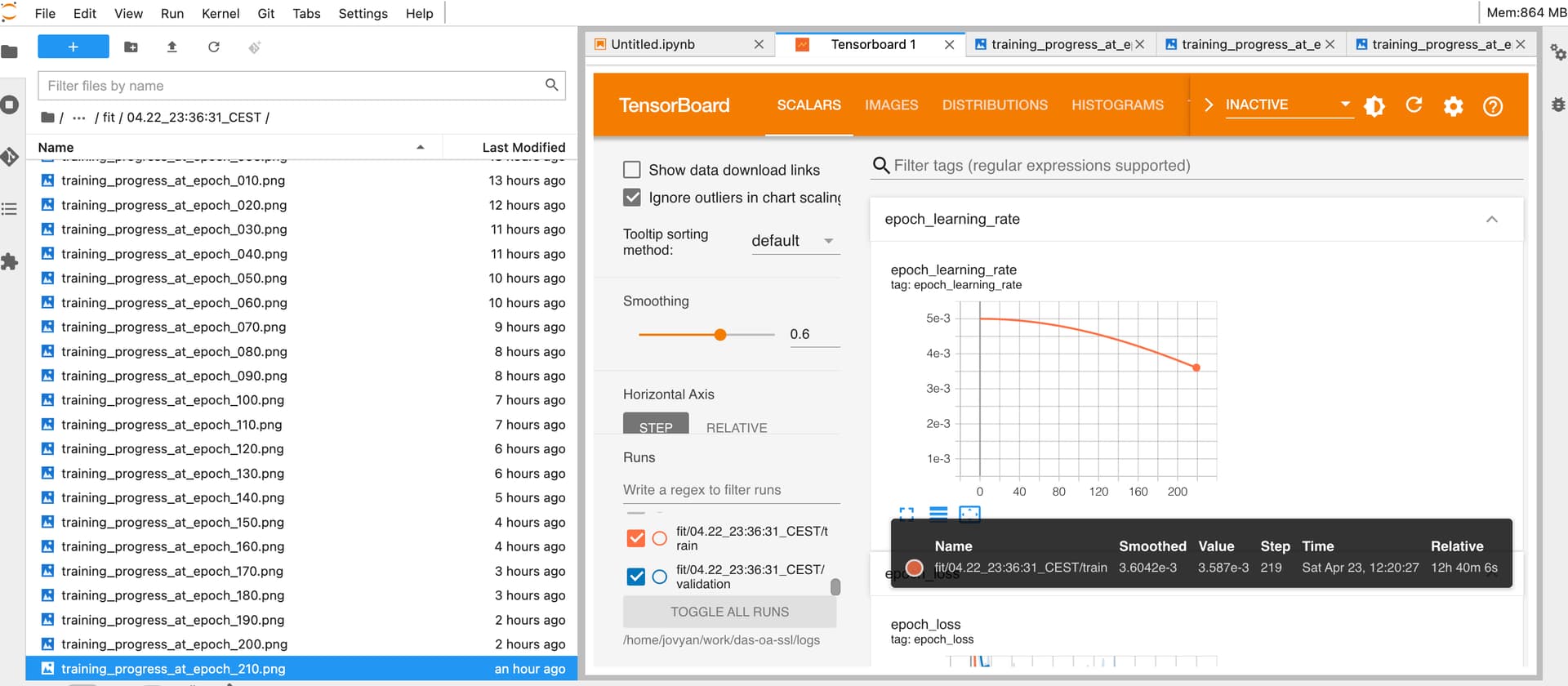
You can also see that some images got saved (e.g. 42 min ago, training progress at epoch 210 for example), but they are all blank. It seems like there’s an issue with saving data during training when my vpn session is disconnected or my laptop goes into sleep mode. What is funny though is that this time data got written to Tensorboard. I can pull up the image at epoch 210 in Tensorboard and you can see the updated learning curve at 12:20 on 23.4 However after that nothing got updated again, training stopped at epoch 210 out of 500.
It might just be the case that training was working fine but then the session crashed when I was trying to reconnect. This would then be a different issue I guess.
I’ll try again today and will start the script from the terminal.
If you have any advice how to avoid such misbehaviour in the future I’d be really grateful.
Thanks.
Thanks for the additional info and followup. I looked at the logs and history of your sessions and I do not see a smoking gun.
However here are my suggestions for a few more things you can try:
- Do not run things from within a jupyter notebook - start things directly from the terminal. Judging by the command you mentioned it seems that you started your models from within a jupyter notebook. Simply open a terminal and start your script.
- We have had some issues with one of the gpus on limited and this got fixed. But I wonder if there are other gpus that are unstable or problematic. Or perhaps there are weird interactions when 2 gpus at the same time are used. Is it possible to try running things with 1 gpu only? I know this will be slower but perhaps it will be more stable. This can let us narrow things down.
Hi @rwagner I suspect you tried to run your training scripts over the weekend? Was it interrupted again?
I think you will need to use something like screen or tmux to do this because otherwise the parent process is always going to get interrupted/closed. Did you already try something like that?
Hi, sorry for getting back late. It’s working fine if I don’t use visual studio code. I’ll let you know in case it should happen again. Thanks!